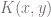Epistemic status: I don’t think anything I’m saying in this post is completely new (eg see https://www.lesswrong.com/posts/Ap4KfkHyxjYPDiqh2/pascal-s-muggle-infinitesimal-priors-and-strong-evidence and https://www.gwern.net/mugging) apart from maybe the meta-probability framing, but it’s an exercise in writing my half-formed thoughts down and trying to explain them clearly.
This post has two parts. In the first I’ll try to pin down the rhetorical sleight of hand in Nick Bostrom article on Pascal’s Mugging, which confused me for a long time. In the second, I’ll muse about the question of how to reason about events that are both “huge if true” and “astronomically unlikely”, and argue with https://nintil.com/pascals-mugging/. In a later post I might analyse the Kolmogorov-complexity-theoretic issues that come up when you try to stop your favourite hard-coded logico-symbolic VNM maximising AI from spending all its time dreaming about winning the intergalactic lottery.
Part 1
Pascal’s Wager is a famous argument that “a rational person should live as though God exists and seek to believe in God. If God does not exist, such a person will have only a finite loss (some pleasures, luxury, etc.), whereas if God does exist, he stands to receive infinite gains (as represented by eternity in Heaven) and avoid infinite losses (an eternity in Hell).” Thus the expected value of praying with true faith is infinite and you should make sure to do it.
In Nick Bostrom’s whimsical article Pascal’s Mugging, Pascal gets asked for money by someone who claims they will use their magical powers to do great deeds of wonder and delight in return.
Pascal: It is possible that you have the magic powers that you claim to have,
https://nickbostrom.com/papers/pascal.pdf
but let me tell you, I give that a very, very low probability.
Mugger: That’s fine. But tell me, how low a probability exactly? Remember,
you might think it all seems implausible, but we are all fallible, right? And
you must admit, from what you’ve already seen and heard, that I am a rather
atypical mugger. And look at my pale countenance, my dark eyes; and note
that I’m dressed in black from top to toe. These are some of the telltale signs
of an Operator of the Seventh Dimension. That’s where I come from and
that’s where the magic work gets done.
Pascal: Gee . . . OK, don’t take this personally, but my credence that you have
these magic powers whereof you speak is about one in a quadrillion.
Mugger: Wow, you are pretty confident in your own ability to tell a liar from
an honest man! But no matter. Let me also ask you, what’s your probability
that I not only have magic powers but that I will also use them to deliver on
any promise – however extravagantly generous it may seem – that I might
make to you tonight?
Pascal: Well, if you really were an Operator from the Seventh Dimension as
you assert, then I suppose it’s not such a stretch to suppose that you might
also be right in this additional claim. So, I’d say one in 10 quadrillion.
Mugger: Good. Now we will do some maths. Let us say that the 10 livres that
you have in your wallet are worth to you the equivalent of one happy day.
Let’s call this quantity of good 1 Util. So I ask you to give up 1 Util. In return,
I could promise to perform the magic tomorrow that will give you an extra
10 quadrillion happy days, i.e. 10 quadrillion Utils. Since you say there is a 1
in 10 quadrillion probability that I will fulfil my promise, this would be a fair
deal. The expected Utility for you would be zero. But I feel generous this
evening, and I will make you a better deal: If you hand me your wallet, I will
perform magic that will give you an extra 1,000 quadrillion happy days
of life.
Pascal: I admit I see no flaw in your mathematics.
Mugger: This is my final offer. You’re not going to pass up a deal that we
have just calculated will give you an expected Utility surplus of nearly 100
Utils, are you? That’s the best offer you are likely to see this year.
Pascal: Is this legitimate? You know, I’ve committed myself to trying to be a
good Christian.
Mugger: Of course it’s legitimate! Think of it as foreign trade. Your currency
is worth a lot in the Seventh Dimension. By agreeing to this transaction, you
give a major boost to our economy. Oh, and did I mention the children?
If only you could see the faces of the sweet little orphans who will be made so
much better off if we get this influx of hard currency – and there are so many
of them, so very, very, very many … .
Pascal: I must confess: I’ve been having doubts about the mathematics of
infinity. Infinite values lead to many strange conclusions and paradoxes. You
know the reasoning that has come to be known as ‘Pascal’s Wager’? Between
you and me, some of the critiques I’ve seen have made me wonder whether I
might not be somehow confused about infinities or about the existence of
infinite values…
Mugger: I assure you, my powers are strictly finite. The offer before you does
not involve infinite values in any way.
Wikipedia claims (as of this posting): “The name refers to Pascal’s Wager, but unlike the wager, it does not require infinite rewards. This sidesteps many objections to the Pascal’s Wager dilemma that are based on the nature of infinity.”
Not infinite, huh? It depends on how you interpret the question “What’s your probability
that I not only have magic powers but that I will also use them to deliver on
ANY promise that I might
make to you tonight?”
Either we assume the mugger can give us X utils (the unit of rewards and desserts, whether just or offered out of the blue) for any possible X we name, and try to put a probability on this as a whole. But this means that the mugger possesses (or can give away) an amount of utility larger than any finite X – which brings us back to infinity again.
Part 2
Or we could think in terms of our prior probability being a function of X, and try to figure out what it is, and what to do (which are importantly different questions) AFTER the mugger names a number.
As it happens, the mugger saying stuff isn’t very important, because it doesn’t cost malicious nerdsnipers anything to claim they have magic powers.
Using Bayes Rule,

Since P(claim | no power) * P(no power) is pretty close to 1, the fraction is not much larger than 1, so the only thing that matters is your original belief in magic/the simulation argument P(power).
But this means that we might as well consider the muggers we might meet tomorrow, aka the ones in our head. As the blog Nintil puts it:
Consider the act of closing the document you are now reading. It is conceivable that a being in Dimension N will kill you if you do so, for not having a permanently open view of Nintil is sacrilegious. What’s the probability of that? Similarly, in dimension L, thinking that Nintil is not the best blog in the world is a hideous act, and is punished by death, even for us inhabitants of the regular universe. What’s the probability of that? Furthermore, should you close Nintil? Should you dare think Nintil is not the best blog ever?
https://nintil.com/pascals-mugging/#wrong
With just the prior probability, the expected utility framework tells you not to give the mugger anything as long as your prior decreases fast enough to make the infinite sums converge to something smaller than the total cost of paying the mugger. Gwern has an argument that if your prior falls off faster than inverse linear then the mugger can get around it by asking you for very small amounts repeatedly, but I think this ignores that the cost of paying the mugger includes transaction costs.
How does one deal with the general possibility of astronomically low probability events having very high impacts?
The natural answer is that beyond a certain point (which varies with one’s anxiety levels) one deals with them by ignoring them.
Note that I am NOT talking about X-risk scenarios ala The Precipice, which are not astronomically low prob but are in fact SCARY HIGH. When I say astronomically low I mean numbers like (1/10^10^10^10) etc.
Anyway, Jose (the author of Nintil) objects to the “ignore things” strategy with an opposing psychiatric diagnosis:
That it seems to condemn us to the epistemic version of bipolar disorder: We are believing that the probability of the mugger being from another dimension is nonzero, and at the same time we are acting as if it were zero.
https://nintil.com/pascals-mugging/#logical
But I think this is fine, and can be defended using a framework of metaprobabilities (eg Jaynes Ap) – see https://www.lesswrong.com/posts/2xmKZu73gZLDEQw7c/probability-knowledge-and-meta-probability for a discussion.
There are many many low probability hypotheses, and we can’t compute exactly how low they are beforehand (because we have other things to do), but we do know some kind of vague meta-probability distribution for each one of them. We know that they are almost certainly low enough that the correct action to take is the one we would if they were zero. (Of course, my “almost certainly” claim leaves behind a sliver of possibility on the meta-level, which leaves me open to Pascal’s Meta-Mugging, a recursive attack which I haven’t figured out how to defend against yet)
The idea is this: The point at which we go back and actually compute how low the prior was is after that hypothesis is raised to our attention by finding strong evidence for it (that shifts our meta-probability distribution). It is after P(claim | no power) drops like a stone (when the claim is repeated by a booming voice from the sky), that we attempt to do the Bayesian calculation more carefully. (If we can find the time while staring in shock at the sky and giving the mugger messiah everything we have)
Jose’s final challenge is:
If you give me $1 (Email me at artir@nintil.com for payment details!), then there is some chance that in a parallel universe ✳^{8✳}8✳8✳8 lives worth living will be created. There is also a similar chance that that same number of lives will be tortured elsewhere. Choose wisely! Agree with me or pay! (Or explain where I went wrong[1] and if I find you convincing, I’ll pay you!)
https://nintil.com/pascals-mugging/#logical
My answer is that there is a difference between my probabilities for things and my actions – I don’t know what the probability of the stuff in the challenge is, but I do know that it is far below my threshold for changing my default action (which is to spend zero of my cold hard cash and an embarrassing percentage of my time on thought experiments in blogposts). If you want to change that, decrease P(Nintil’s evidence | no parallel universes will be harmed in this thought experiment) enough to flatten my meta-probability distribution (currently peaked very close to zero) enough that I’m forced to actually try to calculate my probability distribution.
My actions as opposed to my epistemics, depend on my utility calculations, which depend of where the peaks of my meta-probability distributions are relative to the boundary probability values that would change my actions. Here I suspect that the real reason I don’t pay up is that I’m risk averse + possibly have bounded utilities. Either way, I think my prior of getting exactly X utils[2] from parallel universes from doing a given strange action, falls off super-quadratically with X. This means that beyond a certain point, the higher the claimed utility, the more firmly my meta-distribution is smashed up against zero (and away from the 1/X^2 decision boundary that would be necessary for doing stuff to be positive EV).[3]
Nintil objects to the penalize-the-prior-probability approach by saying
I discussed above that there are good reasons to believe that the probability of the money actually being payed decrease with the amount (less people can pay it), but once we reach the level of the 7th dimensional mugger, it does not. Conditional on the mugger having superpowers, the probability that they have the capability of paying does not seem to change with the amount, at least not by much.
But the mugger actually having superpowers is a question of evidence. Once we know that, the prior is not the only thing that matters. It’s true that once they give us real evidence the shape of the curve P(can give us X utils | evidence, claim) is very different from the prior, but that’s the posterior probability, the prior is only concerned with whether they can give us X utils, not the mechanism.
Summary
We don’t have explicit priors for the results of every possible action we might take.
But we do have rough meta-priors for what they would look like, whose peaks are well under the thresholds for taking action.
We take action to actually check our priors when we see evidence unlikely in worlds with low priors – which widens the meta-priors.
Tall claims about big numbers are not actually evidence.
Gwern points out the flaws in the strategy “unilaterally declare that all probabilities below a certain small probability will be treated as zero.” The correct strategy is “If an event of a certain importance is estimated to have probability below a certain small decision threshold value depending (inversely) on the importance of the event, take the default action you would have taken otherwise, unless evidence emerges that the event’s probability might be above the threshold, in which case look closer.”
Footnotes
[1] Nintil: “If I’m wrong, the correct answer will probably involve the fact that there is a recursive game going on here, whereby the mugger knows that we’ll give a low probability to him being legit and will adjust accordingly, but then we know that he knows, and so on.” – I don’t think this is at all relevant because nothing the mugger says (as opposed to does or shows us) is strong Bayesian evidence with low P(evidence | no powers), which is the only thing that matters apart from the prior.
[2] I’m folding all the risk aversion stuff into the definition of utility, eg if my happiness was logarithmic in wealth then X utils = 2^X dollars. Thus P( can give me X utils) = P( can give me 2^X dollars) and it’s more clear why this would fall off super-quadratically in X.
[3] I do not now, and never have claimed to be a maximising-type agent, but the point is to argue how even such a one would not be mugged.
 and a set of transition probabilities defining the probability of jumping from one state to another. What state you jump to depends only on the current state and not anything that happened before. In this post, I’m going to skip quickly past the details of how Markov chains work, so you might find
and a set of transition probabilities defining the probability of jumping from one state to another. What state you jump to depends only on the current state and not anything that happened before. In this post, I’m going to skip quickly past the details of how Markov chains work, so you might find  and
and 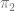 be two probability distributions over a finite set
be two probability distributions over a finite set 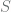 . The total variation distance between them is
. The total variation distance between them is 
 denote an event, or a subset of the sample space
denote an event, or a subset of the sample space  by
by 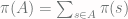 . Then if we pick an event with maximum difference in probability between
. Then if we pick an event with maximum difference in probability between 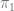 and
and  , that difference is exactly equal to TVD! (It’s pretty easy to prove this by noticing that this event must be the union of all elementary events
, that difference is exactly equal to TVD! (It’s pretty easy to prove this by noticing that this event must be the union of all elementary events 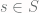 with
with 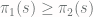 or its complement)
or its complement)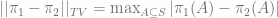
 be a Markov chain with finite state space
be a Markov chain with finite state space 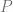 and a unique stationary distribution
and a unique stationary distribution 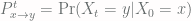 , in other words the probability that when starting in state
, in other words the probability that when starting in state  , after
, after  time steps (or shuffle moves), we are in state
time steps (or shuffle moves), we are in state  .
. to denote the probability distribution of the chain at time
to denote the probability distribution of the chain at time  given that we started in state
given that we started in state  .
.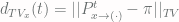 . Now given a tolerance level
. Now given a tolerance level  , the mixing time from state
, the mixing time from state 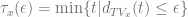 . One can prove that
. One can prove that  decreases monotonically, so if you run the chain for at least
decreases monotonically, so if you run the chain for at least 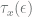 steps starting from
steps starting from  -close to the stationary distribution.
-close to the stationary distribution. 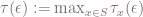 , since we don’t want to have to worry about where we started from.
, since we don’t want to have to worry about where we started from. . But how do we actually compute this mixing time ?!
. But how do we actually compute this mixing time ?! with finite state space
with finite state space 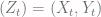 with state space
with state space  such that:
such that:

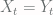 implies
implies  .
. is the original Markov chain’s probability of transitioning from
is the original Markov chain’s probability of transitioning from 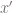 .)
.)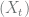 and
and  of the Markov chain
of the Markov chain 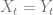 , they evolve
, they evolve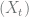 and
and  are individually still faithful copies of
are individually still faithful copies of  even after they couple and start moving in synchrony.
even after they couple and start moving in synchrony.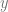 ,
,  . In our card shuffling case, this would correspond to getting a second deck and doing one shuffling move to each deck per time step. This coupling would take a very long time to couple – there’s nothing forcing the two decks to have the same state.
. In our card shuffling case, this would correspond to getting a second deck and doing one shuffling move to each deck per time step. This coupling would take a very long time to couple – there’s nothing forcing the two decks to have the same state. 
 be any subset of our sample space.
be any subset of our sample space.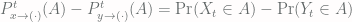
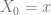 … ‘to those probabilities but I’m not going to write it since it doesn’t affect the argument.)
… ‘to those probabilities but I’m not going to write it since it doesn’t affect the argument.)
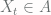 if and only if
if and only if 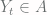 . So those probabilities are equal and they cancel out.
. So those probabilities are equal and they cancel out.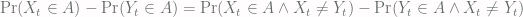
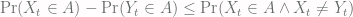 (we drop the negative term)
(we drop the negative term)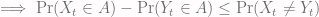 !
!  . By symmetry we can run the same argument to get
. By symmetry we can run the same argument to get 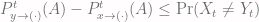 , which means
, which means  . Since this works for any subset
. Since this works for any subset  always, by the definition of the stationary distribution. Then our result is
always, by the definition of the stationary distribution. Then our result is 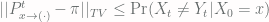 , and since this works for every
, and since this works for every 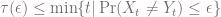
 in each deck to bring to the top. Unfortunately, a little thought shows that if the two decks didn’t start in the same state, they will never couple this way!
in each deck to bring to the top. Unfortunately, a little thought shows that if the two decks didn’t start in the same state, they will never couple this way!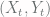 denote the states of the two decks.
denote the states of the two decks. from
from  by moving the j’th card to the top. Call this card C.
by moving the j’th card to the top. Call this card C.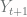 from
from  by moving card C to the top.
by moving card C to the top. — let’s calculate the probability that the card at this position
— let’s calculate the probability that the card at this position be the card in position
be the card in position  in
in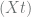 and
and 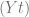 it will always occupy the same position in both decks afterwards. So it is enough to make sure each card in the deck gets picked at least once. This type of ‘gotta catch them all’ problem is known as a
it will always occupy the same position in both decks afterwards. So it is enough to make sure each card in the deck gets picked at least once. This type of ‘gotta catch them all’ problem is known as a  cards for a moment. The probability that a given card C has not
cards for a moment. The probability that a given card C has not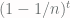 , which is always less than
, which is always less than 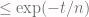 . Adding up these probabilities across all
. Adding up these probabilities across all  .
. 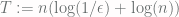 means that the probability of not coupling by time
means that the probability of not coupling by time  is at most
is at most 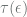 is at most
is at most  .
.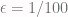 and
and  gives
gives shuffles!
shuffles!  uniformly at random in {1…52}
uniformly at random in {1…52}  to
to  and place it on top.
and place it on top.

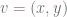 . Now you rotate this vector around the origin by a fixed angle. This gives you a vector
. Now you rotate this vector around the origin by a fixed angle. This gives you a vector  (where
(where  is the rotation matrix). You now round this vector to the nearest integer lattice point, producing a new integer vector
is the rotation matrix). You now round this vector to the nearest integer lattice point, producing a new integer vector ![[Mv]](https://s0.wp.com/latex.php?latex=%5BMv%5D&bg=fffdfd&fg=606666&s=0&c=20201002) . You can repeat this process of rotation and rounding to produce
. You can repeat this process of rotation and rounding to produce ![[M[Mv]], [M[M[Mv]]]](https://s0.wp.com/latex.php?latex=%5BM%5BMv%5D%5D%2C+%5BM%5BM%5BMv%5D%5D%5D&bg=fffdfd&fg=606666&s=0&c=20201002) and so on.
and so on.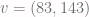 and angle
and angle 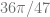

 . After some more hadamard gates you get to measure a bit which is 1 if f(0) equals f(1) and 0 otherwise. Note that you do not get to know either f(0) or f(1), so you haven’t magically gained more information from your single function call, just different information which you could think of as “perpendicular” to the classical way of seeing things.
. After some more hadamard gates you get to measure a bit which is 1 if f(0) equals f(1) and 0 otherwise. Note that you do not get to know either f(0) or f(1), so you haven’t magically gained more information from your single function call, just different information which you could think of as “perpendicular” to the classical way of seeing things. such that working with
such that working with  lets us linearly separate things even though
lets us linearly separate things even though 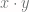 doesn’t work. The kernel trick is that we can actually compute
doesn’t work. The kernel trick is that we can actually compute 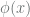 or even work in the high-dimensional
or even work in the high-dimensional  -space at all. So what we do is we take the dot product
-space at all. So what we do is we take the dot product  . Then
. Then 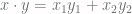 . Suppose our kernel function was
. Suppose our kernel function was  . Then we get
. Then we get  ,which can be written as
,which can be written as  . But this is equal to
. But this is equal to  !
!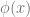 .
.

![1_{[f(0)=f(1)]}](https://s0.wp.com/latex.php?latex=1_%7B%5Bf%280%29%3Df%281%29%5D%7D+&bg=fffdfd&fg=606666&s=0&c=20201002)